亚搏体育 智源王仲远: 全国模子是通往物理AGI之桥
发布日期:2026-06-20 00:54 点击次数:138

2026年6月12—13日,北京中关村国外立异中心,第八届智源大会如约而至。
这场大会的主题消失了二十余个AI行业热度最高的议题,嘉宾声威更是涵盖灵奖得主、顶级科学家、头部AI企业首创东说念主等繁密行业大咖,线下参会东说念主数闭塞万东说念主。
追溯以往的智源大会,会发现一个趣味的“预报”:在谎话语模子最火热的时刻,智源就照旧将全国模子标识在了AI演进的旅途上:谎话语模子——多模态——全国模子——物理AGI,这也使得智源商榷院成为国内最早建议并开展全国模子商榷的科研机构。
2023年智源大会上,杨立昆(YannLeCun)论述了新一代全国模子的倡导;2024年,智源商榷院建议的东说念主工智能大模子技能道路预判,明确指出全国模子是下一代大模子技能;其2024年发布的悟界·Emu3和2025年发布的悟界·Emu3.5,更是全球首个原生多模态全国模子。
基于这些技能千里淀,本年的智源大会上汇集开释了一批优异的科研效果——有媒体称之为“悟界五连发”:原生多模态大模子悟界·Emu3.5;多模态神经科学大模子悟界·Brainμ1.0;AI驱动药物发现模子悟界·OpenComplex2.5;通用全国基座模子悟界·Physis-v0.1与以物理气象展望为中枢的具身大脑悟界·RoboBrainOrca。
而在当来全国模子叙事的海浪中,悟界·Physis-v0.1与悟界·RoboBrainOrca成为了此次智源大会的实足主角。
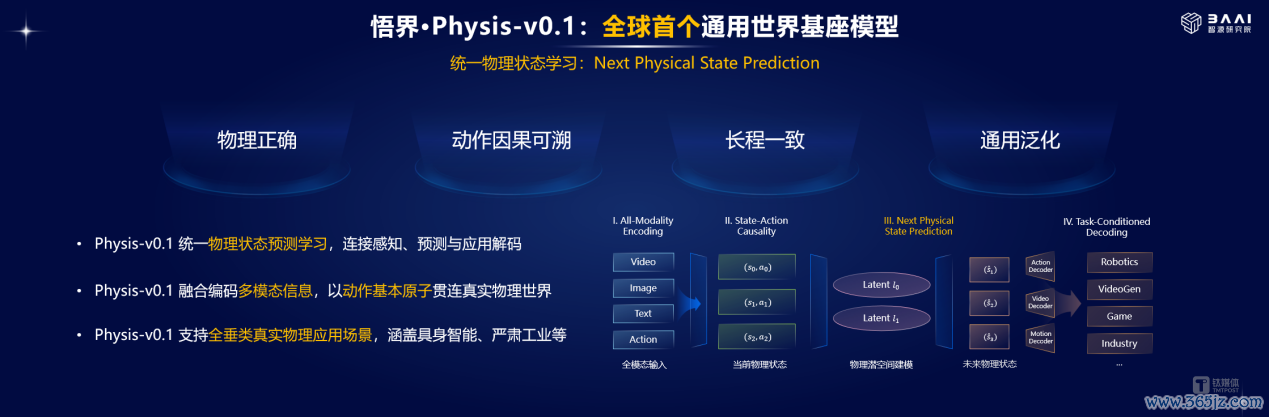
悟界·Physis-v0.1行动全球首个通用全国基座模子,以”展望下一物理气象”为中枢。它不再依赖传统像素、帧级展望有筹谋,而是通过物理隐空间表征学习的确全国启动端正,将视频、深度RGB、3D点云、力触反馈等多模态信息妥洽编码为物理气象Token,让模子得以完成跨场景的通用物理端正强化学习,补助复杂物理场景的长程推理。
而悟界·RoboBrainOrca行动下一个物理气象展望为中枢的具身大脑,构建了"妥洽表征—建模—展望—交互"齐全闭环,具备妥洽表征、因果推演、模态解码三大中枢智力,可同期生成话语想考、视觉展望与动作决策,撑持具身智能机器东说念主在物流场景、旅馆职业场景等的确环境中的长期自主功课。
“智源面前认为现存的全国模子技能可分为四类。最广为东说念主知的应该等于视频生成模子。”王仲远默示,“而面前来看,各人齐在叫的全国模子齐不是的确意旨上的全国模子。这是一种对全国模子的误读,视频生成不等于全国模子,这是智源相等表露的作风。”
事实上,当Sora、VLA、WorldActionModel齐被冠以“全国模子”的名号,行业照实堕入了一场倡导混战。在这个界说尚未拘谨的全新战场上,智源遴选先亮出我方的坐标。在王仲遥望来,这是一次“原来清源”。

以下为与王仲远的对话全文,略有删减:
创投家:为什么智源界说全国模子是通往物理AGI的必经之路?
王仲远:全国模子是面向的确物理全国的下一代基座模子,它让机器东说念主的确"邻接"物理全国,而不是只背诵覆按轨迹。从"展望下一个Token"到"展望下一个物理气象"的变革,咱们认为亦然东说念主工智能的一次首要范式变革,将会产生面向物理全国、物理AI的基座模子降生的契机。
全国模子不仅能感知、邻接、推理的确物理全国的时间、空间、物理端正和物理知识,同期能涵盖文本、视频、深度、力觉、感知等全模态数据,还具备主动交互智力,粗略撑持各式物理全国的下贱诈欺。
通用全国基座模子,不仅需要粗略达成物理的正确,还要粗略有动作因果的可溯和永劫期序列的一致性以及通用泛化智力。咱们拓荒全国基座模子最中枢的原因,等于认为全国模子是具身智能可行的技能措置有筹谋。当今这个产业需要一次中枢技能闭塞,而全国模子等于那座桥。
创投家:据您的不雅察,当来全国模子有哪些技能道路上的不合?
2026世界杯中国压球官网王仲远:本年不错赫然嗅觉到全国模子的热度相等高,好多不同的技能道路、不同的场景模子齐冠以全国模子。浅易来看,智源将现存的全国模子梳理为四种主流技能界说口头:以话语为中心、以像素为中心、以三维结构为中心,以及以视觉表征为中心。
第一类是以以话语为中心的全国模子,包含谎话语模子、VLM、VLA齐是归类为以话语为中心。全国模子的中枢等于粗略让东说念主工智能干涉物理全国,感知、邻接、推理,跟物理全邦交互,话语也有总结好多全国的知识,只是以翰墨的口头抒发,VLM、VLA是把其它模态、其它智力映射到话语空间,是以以话语为中心亦然属于一类全国模子。
第二类是以像素为中心的全国模子,这亦然刻下被误用最庸碌的标的。OpenAI将Sora界说为"WorldSimulator",实质上是在展望下一个2D像素场景,这类模子在视频生成上有庸碌诈欺。但由于覆按数据大量来自影视作品和科幻片,模子会生成不安妥的确物理端正的内容——比如物体编造消失、抵拒重力逻辑、流体能源学失实等。YannLeCun曾经屡次公开品评,生成像素并不等同于邻接物理因果。
第三类是以三维结构为中心的全国模子。李飞飞训诫2024年创办WorldLabs,建议"空间智能"理念,其发布的Marble不错从单张图片生成可交互的历久化3D环境,实质上对准的是数字全国的构建,将来可能诈欺于元天地、游戏场景和数字孪生。但模子重建3D空间不等于邻接全国,几何结构也不代表物理气象。
第四类是以视觉表征为中心的全国模子。比如杨立昆的JEPA系列模子,展望的是视觉表征的压缩,但视觉镶嵌演化不等于物理端正演化。

创投家:智源的全国模子走的是哪一条道路?
王仲远:事实上,yabo888vip中国官方网站咱们认为将来也许会有第五个分类,或者智源尝试的很有可能是第五个分类:等于以话语为中心的分类和以视觉表征为中心的分类的和会,也叫作念潜空间表征。
咱们依然延续悟界·Emu3.5模子的覆按想想,等于将各式翰墨图像视频模态全部压缩,原生妥洽覆按,压缩在消失个语义空间,通过妥洽潜空间表征各式的确物理全国的气象,Decode成为Action、画面或者其它的确物理全国需要的气象。
咱们认为将来妥洽的潜空间建模不单是是视觉空间,而是全模态潜空间。这很有可能是全国模子的下一个可能性旅途,但因为这条旅途还莫得完全走通,是以当今并不贪图界说这个分类,期待来岁和后年,智源再次共享最新效果的时候粗略走通。
创投家:全行业全国模子的卡点到底在那儿?
王仲远:第一个卡点是物理邻接。
当今主流的视频生成模子能作念出一分钟、两分钟的画面,画面看起来没问题,但物理端正是错的。一瓶盖着盖子的水和一瓶没盖的水掉在地上,东说念主类大脑会坐窝预判后果——没盖的水会洒出来,盖着的可能弹起来。这种物理后果的预判,当今的模子完全莫得。咱们不是在教模子生成视频,咱们是在教它邻接物理端正,然后基于这个邻接去展望下一个气象。
第二个卡点是时间一致性。好多模子从五秒到十秒到一分钟,看起来时间跨度在增多,但实质上如故在措置"下一帧像不像"的问题。你给一个瓶子加水,傍边放一个时钟,镜头移开再移归来,时钟走了十秒如故二十秒?模子不知说念。永劫期序列的一致性,不是画面连贯就够了,是瓶子里到底有几许水、时钟走了几许秒、物体的位置关联有莫得转换——这些气象变量必须在时间轴上保持一致。
第三个卡点,亦然最大的卡点——全国模子最终要职业于步履。东说念主类看到瓶子要掉下去,会自动伸手去扶。这个Action不是从视频里学来的,是从物理交互里学来的。咱们需要把多模态感知、物理端正邻接和动作实行三者买通,而不是让它们道不相谋。具身智能在大量网罗的确物理全国的数据,这些数据是挑升旨的,亚搏(中国)一站式服务官方网站但怎样让模子从"看懂"酿成"会作念"又是另一个层面的问题。
这很像往日谎话语模子依赖互联网数据爆发,全国模子也需要一个填塞界限的、的确物理交互的数据底座,才能迎来的确的拐点。
创投家:覆按全国模子,最需要什么样的数据?
王仲远:视频数据是第一性旨趣。
旧年我接受媒体访谈时举过一个例子:一个两岁小女孩,父母从来莫得手把手教过她怎样拆糖果、怎样串蓝莓。但她每天刷短视频,看着屏幕里的姑娘姐吃,看着看着,我方就会了。她通过视频不雅察的确物理全国的交互,然后在我方的全国里尝试、犯错、修正,最终掌合手了这些智力。
视频是她独一的信息输入,但输入的是物理全国的因果链条。她看到"手伸向蓝莓→串起来→送进嘴里",这个画面里包含了动作、物体、空间关联、时间次序,这些不是翰墨描写,而是物理进程自己。这发挥一个中枢趣味:视频数据自然佩戴了物理全国的结构化信息,只是咱们当今还莫得充分挖掘它的后劲。
创投家:是以中枢如故海量的视频数据?
王仲远:视频是底座,但不够。阿谁两岁女孩,她看视频之后还要的确物理交互——我方拿蓝莓、我方串、掉了再捡。这个智力是视频给不了的。
是以第二层数据是的确物理全国的异构感知数据:机器东说念主的要津角度、触觉反馈、力矩变化、传感器读数……这些"身体感受"是视频里莫得的。悟界·Physis在覆按时等于双层结构:底层用海量视频数据拓荒物理全国的倡导模子,表层用的确物理交互数据来精诊治作和决策。两者统筹兼顾。
创投家:您认为全国模子与VLA模子的实质永别是什么?
王仲远:当今的VLA和具身模子,最大的痛点是不具备泛化性,也不具备自我推理和决策智力。
你把它放在覆按过的场景里,它能作念;换一个场景,它就蒙了。因为它的"全国邻接"不是从填塞丰富的物理教训里学来的,而是从有限的、标注过的轨迹里硬背下来的。
像阿谁两岁女孩,要是她只看过三段串蓝莓的视频,她一定学不会;但要是她看了三百段,再加上我方试了几十次,她大脑里的"全国模子"就泛化出来了。
是以咱们的判断是:的确物理全国的数据需要络续累积,最终和视频数据一起,喂给全国基座模子,才能迸发出的确的泛化智力。
好音讯是,当今具身智能和AI硬件正在大量网罗的确数据,这些数据的汇总数积聚,正在逐步涉及物理全国基座模子的爆发点。很像往日谎话语模子需要依赖互联网数据,数据量到了,拐点就来了。
创投家:那VLA和全国模子的末端关联是?
王仲远:VLA是当下、全国模子是异日。VLA也不会被完全取代,但会分层。在特定场景的落地上,VLA依然相等灵验,比如工场里分拣包裹,这种特定任务、特定场景,征集特定数据就能完成,VLA是完全够用的。
但VLA有几个结构性局限:
第一个是模子太大,部署端反应速率不够。的确物理全国实步履作是有频率条目的,机器东说念主要及时反应,VLA的Latency太高了,得志不了。
第二个是刚刚提到的泛化性。它是在一个固定场景里用固定数据训出来的,场景一变就需要重新网罗数据重新覆按。
第三个,亦然最纰谬的,VLA措置不了长程野心和复杂空间物理端正的推理。
创投家:是以VLA是阶段性的过渡有筹谋?
王仲远:你不错把它邻接周详辖下蛋。VLA促进了机器东说念主在特定场景落地,这自己有价值。但它不是末端。十年后,7B、10B致使3B的小模子会越来越顺畅,部署问题会缓解,但底层问题还在。换一个场景,它依然不懂物理,不会推理。
全国模子是措置泛化性和物理推理的末端。短期VLA陆续落地,长期全国模子继承。两条路不是对立的,是奋力于的关联。
创投家:全国模子到底能在哪些场景落地?
王仲远:场景分为两条干线:具身智能和物理仿真引擎。
具身是最信服的场景。总共这个词具身产业正卡在一些中枢技能瓶颈上:机器东说念主的泛化智力。而全国模子等于来措置这个问题的。自然现阶段它还作念不到通用,但会全辖下蛋,在措置具体场景问题的进程中不休积聚。
梦想态的全国基座模子既不错用于具身,也不错用于物理仿真、科学执行,包括其它物理全国的的确场景,诈欺应该相等庸碌。
创投家:全国模子在数据网罗层面的价值,是不是主要等于生成合成数据?
王仲远:生成数据是其中之一,但远不是主要价值。咱们自然不否定视频生成模子在无东说念主驾驶、自动驾驶和具身场景齐有私有价值——悟界·Physis和悟界·RoboBrainOrca也照实展示了的确的画面生成智力。但要是把全国模子只当成"数据生成器",那就把它用小了。
创投家:那在数据层面,它更大的价值是什么?
王仲远:是决策前置。全国模子的确强调的是:基于刻下Context和气象,展望异日可能发生的各式情况,然后作念出最优决策。这跟《奇异博士》有点像——他不是只可看到一种异日,他能看到几千种异日,然后遴选那一种最佳的截至。
创投家:这和数据网罗有什么关联?
王仲远:关联在于,它能指引你采什么数据。传统数据网罗是"扫街"式的——开着车满全国跑,遭受什么采什么。有了全国模子,你不错先问它:要是我要措置这个场景的泛化问题,哪些物理气象变量最纰谬?哪些旯旮情况最可能发生?然后我有针对性地去网罗,而不是盲目堆数据。这么数据遵守是数目级的提高。
全国模子不是造数据的器用,而是野心数据需求的大脑。基于对异日气象的展望,它能告诉你"缺哪块数据",而不是"帮你生成一堆不足为训的数据"。悟界·Physis和悟界·RoboBrainOrca照实能生成画面,但那只是考据技巧,不是中枢诈欺。
创投家:覆按全国模子对算力的条目是不是更高?
王仲远:要看你走哪条路。全国模子面前技能道路莫得完全拘谨,不同道路对算力的需求毫不研讨。
要是你把话语体系包进去,走生成道路,那算力需求等于海量的,和GPT-4、Sora一个量级。这些道路自己亦然全国模子技能旅途的一种探索,但它们自然等于算力黑洞。
创投家:智源走的是什么道路?对算力条目高吗?
王仲远:悟界·Physis的瞎想想路是不包含话语,专注在视觉和物理气象的Latent学习。Latent学习方法的实质是极致压缩——不是把总共这个词全国打成像素重建,而是在隐空间里学习物理气象的空洞默示。这省下来的算力是数目级的。是以咱们当今鼓舞悟界·Physis,算力需求是相对可控的,不需要堆万卡集群才能跑。
创投家:您预期全国模子距离技能教训还需要多久?各人齐以为谎话语模子上中好意思的差距是六到十二个月,那全国模子呢?
王仲远:必须承认物理AI特出是全国基座模子的商榷,全全国范围依然处在相等早期,致使是倡导和技能旅途齐远莫得拘谨,因此咱们的模子才称之为0.1版块。距离教训,至少还需要三到五年,致使更久。科研探索这件事说不准,可能卡在一个难点三五年也没闭塞,但也可能短暂迎来技能爆发。
而谢全国模子这个赛说念上亚搏体育,我以为中好意思莫得差距。
 备案号:
备案号: